

By: Alex Cline, Alice Helliwell, Brian Ball, David Freeborn and Kevin Loi-Heng
Project supported by the Ethics Institute, the Internet Democracy Initiative and NULab, at Northeastern University
What can computational methods–particularly artificial intelligence (AI)–tell us about AI ethics? We are a group of researchers who have become intrigued by what such methods can add to philosophical studies, and vice versa. In the programmes at Northeastern University London,[1] we are interested in AI ethics. Education in this subject forms an integral part of our teaching, particularly on our MA Philosophy and Artificial Intelligence and our MSc AI and Ethics. Our students have a wide range of backgrounds, (though many have been trained in either philosophy or computer/data science). Our aim is to provide philosophical and computational education simultaneously, to equip students with the skills they need to responsibly engage with AI technology.
Given this ethos, we have decided to turn use of computational methodologies on our own practice, by investigating some of our philosophy courses on these programmes. Our aim is to gain insight into our pedagogical approach and to develop a project which we can (hopefully) share with our students. In fact, one of the researchers on this project (Kevin Loi-Heng) is an alumnus of our MSc! So far, we have found this process to be surprising and rewarding.
In order to test our thought that computational tools can be useful for pedagogical and philosophical goals, we decided to conduct a computational analysis of the texts we set for students across two courses: AI and Data Ethics, and Advanced Topics in Responsible AI. We have (rather grandiosely) called this our ‘canon analysis’. Of course, we did not gather these papers with the intention that they truly be a ‘canon’ of AI ethics. We have curated them over several years, and after completing both courses, we want our students to have covered a variety of classic and current topics in AI ethics and responsible AI. Having gathered the recommended texts for these courses, we utilised some standard Python-based natural language processing (NLP) techniques to analyse our corpus of texts.
Absolute Word-frequency Analysis
The first analytic tool we turned on our corpus was a word frequency counter. This simple computational technique counts the number of times a word appears in a document, or collection of documents. This allowed us to identify the words that appear most frequently in our collection of papers, and produce the word cloud below (where the most frequently used words appear largest in size):

To our surprise, we found that across our two courses, the highest frequency unique word used was ‘human’! Perhaps, as scholars in the ‘humanities’ this shouldn’t have been unexpected to us, however we consider this corpus of texts to be primarily concerned with technology and ethics. It may be that the authors used on our courses are contrasting humans with the data (2nd most common) and machines (8th most common) that are their explicit focuses.
Term frequency itself has limited utility for telling us about unique features of a corpus of texts. It could be, for example, that (contrary to the conjecture at the end of the last paragraph) ‘human’ is something that comes up in philosophical works in general. To find out more about the unique features of this body of texts, we conducted another analysis.
Relative Word Frequency Analysis
Surprised at the most frequent word being ‘human’ we decided to analyse word-frequency further. We ran another measure on the corpus: a TF-IDF (Term Frequency–Inverse Document Frequency). This NLP technique is typically used to evaluate the relative importance of a word in a document compared to its importance in the corpus as a whole. Rather than simply counting the frequency of use for each word, a TF-IDF can show which words are more common in our AI Ethics corpus compared to a larger, or alternative, corpus of texts.
Of course, in this case we were not just interested here in individual papers, but the body of works (our AI ethics ‘canon’) as a whole. In order to complete a TF-IDF measure then, we required a contrasting corpus of texts. It just so happened that, following the Wittgenstein and AI conference and edited collections some of us had recently produced (see volume 1 and volume 2), we had a ‘Wittgenstein Corpus’ available; a body of papers (accessed through JSTOR) discussing the work of Wittgenstein.
| Top 10 words: AI Ethics Canon | Top 10 words: Wittgenstein Corpus |
| human | philosophy |
| ethic | Wittgenstein |
| moral | philosophical |
| robot | language |
| data | theory |
| system | political |
| technology | social |
| design | review |
| agent | science |
| develop | knowledge |
When we compare these two analyses, we start to see the relative importance of these terms in the text. ‘Human’, for example, is not just the most frequent unique word, but it’s particularly important in the AI ethics papers compared to works discussing Wittgenstein. ‘Wittgenstein’ is the second most important word in the Wittenstein papers (a comforting sign that our analysis was working).
Using AI: Semantic clustering
Few nowadays would consider the techniques we have discussed so far to involve AI: in particular, the computational methods employed operate directly on textual data, here the full papers from our two course reading lists. Since research papers are written in natural language, they need to be converted into a numerical format that a computer can read and interpret if contemporary AI techniques are to be deployed on them. We did this using SciBERT, a state-of-the-art transformer model pre-trained on scientific texts. This allowed us to turn each paper into a unique vector (essentially a high-dimensional mathematical fingerprint) that captures the meaning of the text.
Once we had numerical representations of each paper, we compared them to each other using cosine similarity. This helped us measure how closely related different papers are based on their content. A similarity score of 1 means two papers are essentially the same, while a score close to 0 means they are very different.
Using this measure of similarity we attempted to draw out where papers in our canon were grouped together around different subjects and themes. To examine this, we utilised a couple of methods. First, we applied K-Means clustering,an unsupervised machine learning technique that groups papers into clusters based on their similarity. It works on unlabeled data (without defined categories or groups). The algorithm first randomly selects central points (centroids), then uses algorithms to automatically find common themes and structures in the data. We repeated the clustering with different k values to find different groupings. By experimenting with different k values we determined the best number of clusters. For this we used techniques like the Elbow Method and Silhouette Score to find a suitable number given the tradeoff between better representing the data and using more clusters. We decided on six clusters to move forwards.

K-means struggles to deal with as many dimensions as provided by SciBERT’s analysis of the papers, so we had to process the data further. We did a principal component analysis (PCA) to reduce the dimensionality of the data. PCA is a linear algebra technique which finds directions in the data that can explain the greatest proportion of variance. We utilised 112 components, as this explained 95% of the variance in our data. Having reduced the dimensionality of our data, we conducted K-means clustering.
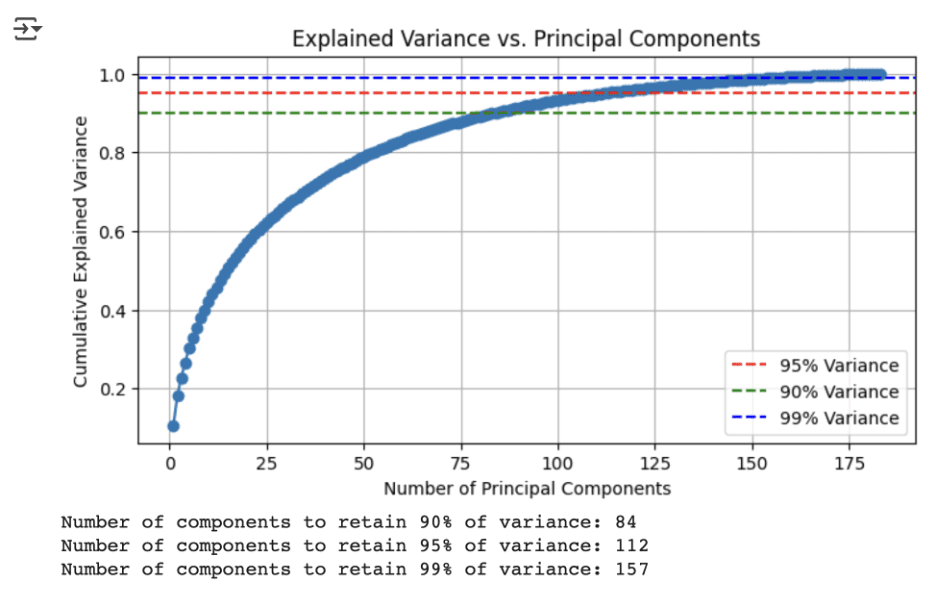
To ensure that the clustering results were meaningful, we checked whether each paper had the highest similarity to the average of its assigned cluster. The fact that 100% of papers were most similar to their own cluster’s average reassured us that the model was making reasonable groupings. In order to visualise these clusters, we needed to conduct further processing on this data, again using PCA, to reduce the clusters to two dimensions. This two dimensional data could then be visualised on a series of graphs, using difference

When we looked at which papers fell in each cluster, however, we had a hard time interpreting these clusters. We couldn’t clearly determine which topic/s in AI ethics were key for each cluster. This was likely due to the high dimensionality, and the small number of papers included in our analysis. We are reminded that contemporary AI relies on BIG data! We therefore tried an alternative method for grouping the papers in our canon.
Using AI: Topic Analysis
We next used the Latent Dirichlet Allocation (LDA) method to examine the canon, to see if the paper groupings produced made more sense to us. LDA is also an unsupervised machine learning approach. However, unlike K-means, we can use LDA to gather papers under topics, and to then produce a list of words for each topic, making it more interpretable.
LDA is a soft clustering method, which models probability distributions over words and documents. When we use LDA to analyse papers, it treats each paper as a collection of words – i.e. it does not consider the position of each word in the paper (unlike SciBERT). LDA builds a model of the whole corpus, and tries to identify distinct topics by finding correlations between words. Frequent co-occurrence of words suggests they are related in a topic, whereas non-co-occurrence of words suggests they are not related in a topic.
Our output from LDA is a series of probabilities. For each paper we get a probability that it falls in each topic (six topics). A paper is therefore not just assigned to one topic – instead, it can have a high probability of concerning multiple topics. This may be for good reason – for example, an overview paper might end up having a high probability of concerning e.g. ‘privacy’ ‘AI design’ and ‘robot agency’ (etc).
From examining the topics uncovered in this manner, we felt like we could make some sense of them. We identified the broad themes of each topic as follows:
Topic clusters:
0: Social, social media, gender, culture
1: Superintelligence
2: Applied issues such as sustainability, health, and the arts
3: Robots, personhood, and artificial agency
4: Design, responsibility
5: Privacy and risk

These topics certainly seemed to us to have some internal unity (as indicated), but they could also be seen not to overlap one another in problematic ways. Looking at the percentage of the papers in one topic (the row in the above table) that overlapped with papers in the other topic (in the columns), we found both that the overlap was not in general too great, and that such overlap as there was could be readily interpreted. For example, 52.9% of the papers on superintelligence could also be viewed as concerned with a topic involving the notion of artificial agency, which is understandable given that ethical concerns around the former appeal to the latter; moreover, looking at the column corresponding to superintelligence, we see that it is entirely blue, meaning that none of the other topics overlapped much with it – and indeed, our impression from working within the field is that this topic does, as a matter of sociological fact about the AI ethics community, stand somewhat apart.
What can AI tell us about philosophy
AI-powered knowledge discovery is being widely applied in STEM fields like biology and genomics, and for drug-discovery etc.; but these advancements have not, on the whole, extended into the humanities and social sciences, including philosophy (which has historically played an integral part in AI development). Some progress has been made in using NLP techniques, with the availability of pre-trained LLMs which offer some promising utility to help process textual data. Our research leverages these methods to begin to make sense of a growing academic literature in AI ethics – at least how we have presented it to students. In the future, we hope to continue our analysis of AI ethics literature, and share this with our students to gain their perspective of how this analysis meshes with their understanding of our courses.
[1] Alex Cline has now started working for Queen Mary University London.

