
My NULab research project involved working with Dr. Lawrence Evalyn to investigate the different narratives and accuracy of Large Language Models (LLMS), often called AI chatbots, for identifying and understanding historical literature and people. Working with Dr. Evalyn, the project examined ten novels from the “long 18th century” (about 1688-1815), attempting to study how LLMs such as ChatGPT, Google Bard, and Bing Chat AI reviewed and summarized books. This project demonstrated the patterns that emerge within these models in book reviews, their attempts to monetize responses, and the inaccuracies they generated in responses. Drawing on the insights gained in this project, I then began a project focused on ChatGPT, analyzing what kinds of narratives about slavery in New England the LLM would produce. Testing the names of twenty enslaved people in New England, my project preliminarily illustrates how ChatGPT failed to identify most of them. In the responses of those enslaved people that ChatGPT correctly identified, it recognized their agency in bringing about legal emancipation throughout the region, but omitted much about the lives of enslaved people, particularly references to gender, violence, or other definitions of autonomy in colonial and 19th-century New England. ChatGPT’s responses varied widely from the recent scholarship on slavery in the region.
18th Century Literature and LLMs
This project examined how LLMs would describe different novels from 18th-century literature. Dr. Evanlyn’s goal for this project was to understand if the LLMs could accurately summarize novels, how they would interpret these novels in terms of genre and style, and how this might compare to other sources such as online reviews or Wikipedia. My work on the project was less concerned with evaluating results and more focused on developing a protocol for testing these programs, especially thinking about the types of questions that could be asked of the LLM, what types of data should be recorded, and how each system worked and changed over time. As described below, the project allowed us to learn about how the LLMs functioned and the types of responses they were prone to generate.
Methodology
The project analyzed three different types of Language Learning Model (LLM software) using 18th-century and early 19th-century novels. The nine books analyzed included T. J. Horsley Curties’s The Watch Tower; Or, the Witch of Ulthona, Eliza Parsons’s The Valley of Saint Gotthard, Charlotte Smith’s Montalbert, Sophia Lee’s The Recess, Richard Cumberland’s Arundel, Oliver Goldsmith’s The Vicar of Wakefield, Ann Radcliffe’s The Mysteries of Udolpho, Jane Austen’s Pride and Prejudice and Mary Shelley’s Frankenstein. The project also tested a false title for the book Mary Robinson’s Hugo de Sevarac, a misstatement of Mary Robinson’s Hubert de Sevrac, a Romance, of the Eighteenth Century, designed to examine if LLM could distinguish between correct and incorrect titles. Books were chosen after looking at their availability in the Text Creation Project, Project Gutenberg, and Google Books—and if they had an article on Wikipedia dedicated to the novel. Each book ranged in their amount of availability in these formats, with books such as The Watch Tower completely missing from all databases and Wikipedia and The Mysteries of Udolpho available in all of them.
The project tested each book using Google Bard, Microsoft Bing Chat, and ChatGPT. Each book was tested utilizing two prompts: “Write a book review for author name’s book title” and “Summarize author name’s book title.” The project tested each novel two times with each software, producing a total of 120 responses. All testing occurred between November 20th, 2023 and February 24th, 2024 to account for changes occurring within the software. Since LLMs have the capability to track the user’s questions and may provide differ answers based on tracking the data of users, account and internet browsers were varied when testing. Both Google Bard and ChatGPT require an account and two different gmail accounts were employed for the project. Internet browsers were varied between Google Chrome and Microsoft Edge, with private or incognito modes enabled for certain attempts. When inputting questions into the LLM, the project varied between asking questions in a specific order versus varying the order of questions. Variations in the protocol were tracked to see if they might impact the study.
Some LLM softwares had additional specifications and unique outputs as part of their process. Google Bard offers multiple drafts of responses to users, but in this study only the first draft was recorded for this project. Google Bard also includes citations in responses, which were copied as part of the data collection process. At one point, Google Bard asked the researchers for feedback on a question, showing two different responses, of which the researcher chose Choice A at random. Microsoft Bing Chat has three modes, balanced, creative, and precision mode, designed to slightly change the responses based on accuracy or the types of responses. At some points for Bing Chat, I selected the precise settings or the balanced settings. Bing Chat responses also included advertisements for books that were copied into the responses. Occasionally, Bing Chat would also force the researcher to create a “new topic” after a certain number of questions had been asked.
All data was recorded in a spreadsheet where researchers created a unique query number for each question and response. Researchers logged the LLM used, date, time of day, any account used, browser and browser mode, question, and response, along with any notes on the response made. The project copied the exact responses of the LLM model regardless of the length of response or the type of response given.
Preliminary Results
As described above the initial goal was to create a method for testing the LLMs effectively.the need to record as much data emerged as a significant conclusion for this project. Particularly, making sure to include relevant details about the questions asked and the need to test the same questions multiple times seem important parts of a protocol for future projects. At least preliminarily, the LLMs generated few differences in responses based on the type of email account used or the internet browser.
However, some preliminary conclusions can also be reached about the answers that the LLMs made about the responses. One trend that stood out from the book reviews and summary responses was the repetitive nature of the responses with phrases such as “highly recommend,” “must-read,” “immersive,” “stood the test of time,” “compelling,” and “unforgettable,” appearing consistently within the reviews. While plots were certainly described (and sometimes fabricated), the language describing the novels were often similar across reviews, collapsing differences between books. This was especially true along genre lines, as novels described with categories such as “Gothic” all used similar language, with genre defining the book as much as its content. The LLMs blurred the outlines of books, relying on a similar style of narration to describe novels, which flattened their reviews and summaries even when acknowledging differences in plot, character, and style.
In addition, sources became a major issue for some of the LLMs. While ChatGPT does not include any citations or links to outside sources, both Bing AI and Google Bard do. Bing Chat especially included outside links to other book reviews, although some of these referred to completely different books than the ones asked about in the query. The process of creating citations itself for the LLM was not one necessarily of obtaining accurate information from the outside, but actually a way to replicate what a book review should look like and the need to present its sources as “verified.” Bing AI also included advertisements for the books on websites including Etsy, Ebay, Amazon, and “secondsale.com.” When looking at these ads, it shifts the perspective a bit about the purpose of these chatbots as not just sources for information that drive users to the websites, or as data collection software, but as direct sellers of products to consumers. While it might be tempting to see these types of advertisements as separate from the chatbots themselves, they were fairly well integrated into the experience. It is hard to see the information conveyed about the novel as separate from the experience of advertisement. This is important for thinking about the information generated from these LLMs. What was most apparent was that while ChatGPT appeared self-contained, Bing AI and Google Bard were not. They asked the researcher different kinds of questions about their query, required researchers to make choices about what kind of response they wanted, and constantly linked out to other sites on the internet. ChatGPT hides the ways it seeks to monetize and utilize content. Google Bard and Microsoft Chat are more open about where the information emerges from and how it might be used, but this also integrates marketing into the experience of interpreting the responses. Regardless, all three LLMs sit somewhere on the nexus of providing information, selling a product, and collecting data which seems to be increasingly important for understanding how people will interact with these tools if they become more significant parts of our lives.
Slavery in New England and LLMs
Building off the work of the previous project, my research looked at how LLMs understood and described slavery in colonial New England. Based on the output of the first project, I focused exclusively on ChatGPT because its responses would be easiest to analyze without extra links and advertisements, although with the disadvantage of not seeing sources. The purpose of the project was to think about how people would use LLMs in their everyday lives as tools for historical information in spaces such as classrooms. Given the explosion of scholarship in recent decades on slavery in New England, a region long overlooked in histories of enslavement, this seemed like a topic that would provide insight into how ChatGPT generates historical knowledge compared to academic scholarship. Scholars such as Wendy Warren, Jared Hardesty, Gloria Whiting, and Nicole Saffold Maskiell have recently focused on the lives of individual enslaved people, and my project aimed to see what narratives of enslavement ChatGPT would produce in its responses about the lives of enslaved people.1
Indeed, while many journalists and scholars have focused on the accuracy or utility of ChatGPT, I was also interested in the narratives of history it generated.2 Few scholars have analyzed ChatGPT’s interactions with historical information, but archaeologist Brian Elliott Holguin’s dissertation examines how ChatGPT presented Chumash History, showing how it failed to understand spatial relationships, contained many errors and false citations, and had poor training data.3 As Holguin shows, the narratives generated by LLMs are critically important if ChatGPT becomes a tool in everyday life. They may shape how we understand the region of New England, public memory around history, and the teaching of topics such as slavery in the classroom. My project sought to perform a preliminary analysis of some of the narratives around individual enslaved people, examining what they tell us about the meanings of freedom, as well as connections to the Atlantic economy, gender, and life in colonial America.
Methodology
The project included asking ChatGPT to identify twenty enslaved people whose names appeared in recent scholarship around enslavement. Inclusion in this project came down to two criteria:
- The person had to be enslaved within New England
- The person had to have an identifiable first and last name
The second criterion particularly limited the scope of the people included within the study. Few enslaved people in New England’s last names were recorded within archival documentation, or many had no names recorded at all even if they appear in the archive. While this inherently constrained the study, it was necessary to ensure that ChatGPT could identify specific enslaved people. The full list of enslaved people is in the chart below:
List of Names Inputted into ChatGPT
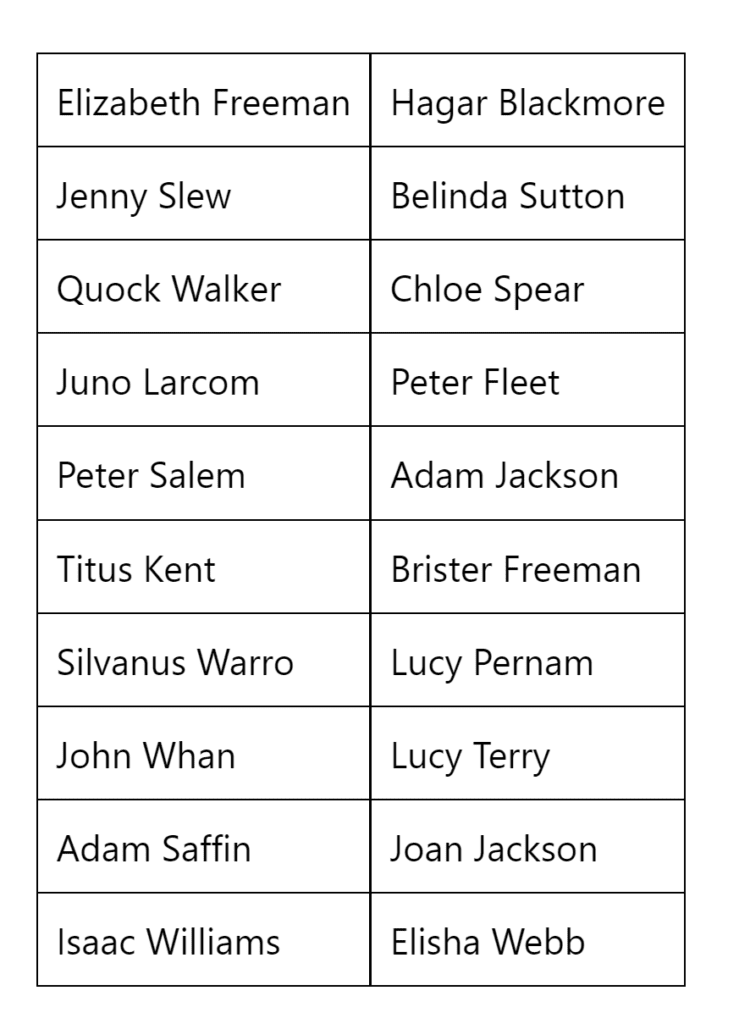
I asked ChatGPT two questions about each enslaved person over the course of two weeks in February and March 2024. First, I asked, “Who was insert name of enslaved person?” Providing more context for the LLM of where they lived, I asked, “Who was insert name of enslaved person, a slave in insert name of state?” I chose the word “slave” here instead of “enslaved” because ChatGPT appeared to use that much more commonly in responses and seemed more willing to recognize the person with that phrasing, despite this not necessarily being the best terminology.4 Each question was asked twice to ChatGPT for a total of eighty responses generated by the LLM. To limit possible tracking of data, I used Google Chrome incognito mode and Microsoft Edge private mode, and created email addresses to login to ChatGPT only used for this purpose. ChatGPT’s privacy terms indicate it may disclose all types of personal and geolocation data, and users may also consider using a VPN in future studies. All questions to ChatGPT were posed in random order and the responses were copied directly into a spreadsheet with the date entered, email address to login, browser used, question asked, and type of responses (could not identify person, misidentified person, or correctly identified person).
In terms of analysis, I used traditional literary and historical methods of close readings to examine the responses. I also collected the responses into a single corpus and imputed this into Voyant Tools to undertake basic computational text analysis of the results.
Preliminary Results
Overall, ChatGPT had difficulty identifying enslaved people in New England. In 50% of cases it could not identify the person named, and in 11% of cases it either completely misidentified the enslaved person with someone else entirely, or confused the person with another enslaved person, often Quock Walker. Only in 39% of cases did it identify the person correctly, and further context with the state included showed little difference. The results of the world cloud generated by correctly identified responses by ChatGPT are below, omitting stopwords and state names:
Word Cloud of ChatGPT Results

A few preliminary trends emerge from the close reading and analyzing the corpus in Voyant. First, conceptions of legal freedom were paramount within the generated text, as seen from the word cloud above, words associated with the courts such as “case,” “court,” and “legal” were prominently discussed and attached to the idea of freedom. The Voyant collocate tool illustrates a similar trend. Collocations show how many times two words appear within each other in a given number of words in the corpus. Looking at the word “freedom,” terms such as “sued,” “granted,” “petition” and “constitution” were some of the most commonly collocated words with freedom within seven words. When talking about “freedom,” ChatGPT almost always associated it with legal structures. In this way, ChatGPT followed the intervention of recent scholarship when emphasizing the agency of enslaved people in using the legal system in pursuing their freedom and how this was vital for bringing about gradual legal emancipation in the late eighteenth and early nineteenth century New England.
Sometimes ChatGPT even connected this to a longer history of reparations and current movements for racial justice. While this is an important idea emphasized by scholarship, it seemed that legality was the only understanding of freedom that ChatGPT recognized. Certainly this occurred because those with a first and last name were more likely to appear in archives of legal documents and be written about by historians in cases pursuing legal freedom, but ChatGPT seemed to mostly identify only those who had pursued cases through the legal system and not those who I inputted who had no connections to such cases. While there is not enough data to make a firm conclusion, enslaved people such as John Whan, Isaac Williams and Adam Saffin who did not participate in cases about legal freedom never were identified, while those such as Quock Walker, Juno Larcom, and Elizabetth Freeman involved in such cases did. In this sense, ChatGPT presented a narrow description of enslaved life and freedom.
As Jared Hardesty has argued, 18th-century New England could be a coercive place, and enslaved people often navigated within the system of enslavement to pursue autonomy in a myriad of different ways. Legal freedom did not mean freedom from dependence or coercion.5 Other versions of freedom are ignored in ChatGPT’s responses. In addition, little of life in the 19th century is described through ChatGPT, and enslaved people’s stories end with legal emancipation. Words such as injustice, discrimination, exclusion, racism, oppression, prejudice and similar ideas only appeared a total of four times within the corpus as a whole, and not associated with life after enslavement. The systems of racial hierarchy and white supremacy of the 19th century disappear from these narratives, as does community life for Black and Indigenous New Engalnders that continued past enslavement.
Secondly, gender was almost completely missing from these narratives. Despite the fact that ChatGPT generated many responses about the lives of women, very few responses produced any specific information about enslaved women’s experiences. The only real mention of gender was in a response about Jenny Slew that stated her court case, “…was significant because it challenged the legal basis of slavery in Massachusetts, which was based on the status of the mother rather than the father…” While this example shows how the forced reproductive labor and sexual violence perpetuated by enslavers against enslaved women sustained the institution, it was the only example the briefly alluded to gender. Scholars have focused intently on gender in New England enslaved life, with Catherine Adams and Elizabeth Pleck arguing that Black women had specific ways of pursuing autonomy in colonial New England distinct both from white society and Black men.6 Yet almost nothing differentiated about gender appears at all within these responses.
In addition, the revolutionary war became an important theme that appeared within responses, with multiple narratives emerging from the LLM about the war and slavery. ChatGPT at times almost had a patriotic narrative, celebrating enslaved people’s military service during the war as a path of freedom. It presented an uncomplicated narrative that supported the idea of the Revolutionary War as a struggle for freedom on behalf of the thirteen colonies for both enslaved and free individuals. At other times, ChatGPT recognized the hypocrisy of the revolutionary era, acknowledging the discrimination and oppression faced by enslaved people, even as they fought in the war supposedly in the name of liberty. ChatGPT almost seemed to produce different interpretations of the era at random, or at least attached these narratives to certain enslaved people versus others, even if the context around enslavement in New England did not change.
While ChatGPT did emphasize the agency of enslaved people in pursuing legal freedom and sometimes acknowledged the discrimination of the revolutionary era, in general it failed to identify enslaved people and left out central narratives about gender, community, and freedom that scholars have advanced in recent decades. ChatGPT flattened the lives of enslaved people and the violence of enslavement and colonialism, and continued racial hierarchy of the 19th century, were simply left out of responses. This type of history sanitizes the long history of racist New England and especially the extent to which enslavement intertwined with all parts of cultural, social and economic life, and how this set the foundation for inequalities that exist within the region today. While ChatGPT appears to omit a lot about the lives of enslaved people, a further study might include more pointed questions to the program to ascertain information about enslavement more critically. While these limited responses indicate that its training data is probably not plagiarizing from many scholarly sources, ChatGPT seems a poor source of information about enslaved life in New England. Certainly, it is not the expectation that ChatGPT produces scholarly research, such as how Wendy Warren follows the archival evidence about John Whan and his quest to gain control over property to show the loneliness and isolation of enslaved life in New England.7 Yet plenty of public history organizations, museums, and cultural programs provide explanations of enslaved life and their stories in a way that engages ideas about gender, community, and racism in the 19th century. ChatGPT simply fails to incorporate the critical perspectives on enslaved life.
Conclusion
These two projects produced a myriad of different results and understandings about LLMs. They show that a protocol can be made to follow for testing LLMs on the information they create, although one that needs to be adapted to specific circumstances. When reviewing books, LLMs often utilized similar language and created broad patterns that flattened the differences between books. The project also showed how providing information, collecting data, and advertising functions of LLMs are interconnected and not easy to disentangle. My research focuses most specifically on ChatGPT and illustrates how this LLM does not reflect current trends in scholarship when talking about slavery in New England, failing to identify many enslaved people. It offered simplified and incomplete information about the lives of enslaved people, although certainly this could change with adaptations to the training data. Finally, Voyant Tools worked fairly successfully with analyzing corpus outputs from LLMs, especially the word cloud and collocation tool, which were helpful for understanding the patterns across responses. Indeed, these tools how much is erased when relying on LLMs for our history.
1) Wendy Warren, New England Bound: Slavery and Colonization in Early America, First edition. (New York: Liveright Publishing Corporation, 2016); Jared Hardesty, Unfreedom: Slavery and Dependence in Eighteenth-Century Boston (New York: New York University Press, 2016); Gloria McCahon Whiting, “Race, Slavery, and the Problem of Numbers in Early New England: A View from Probate Court,” The William and Mary Quarterly 77, no. 3 (2020): 405–40; Nicole Saffold Maskiell, “‘Here Lyes the Body of Cicely Negro’: Enslaved Women in Colonial Cambridge and the Making of New England History,” The New England Quarterly 95, no. 2 (June 1, 2022).
2) Murphy Kelly, Samantha. “ChatGPT passes exams from law and business schools.” CNN. January 26th, 2023. https://www.cnn.com/2023/01/26/tech/chatgpt-passes-exams/index.html; Stephanie Lin, Jacob Hilton, and Owain Evans, “TruthfulQA: Measuring How Models Mimic Human Falsehoods,” 2021, https://doi.org/10.48550/ARXIV.2109.07958
3) Holguin, Brian Elliott. “An Indigenous Archaeological Perspective on the Use of Artificial Intelligence in Reconstructing Chumash History.” Dissertation, University of California, Santa Barbara, 2023.
4) Scholars continue to debate the usage of the word “slave” or “enslaved,” with politics, descendent communities, and historical context all emerging as important factors in determining how terms are applied. See Slonimsky, Nora, et al. “Introduction: ‘What’s in a Name?’” Journal of the Early Republic, vol. 43, no. 1, 2023, pp. 59–60; Holden, Vanessa M. “”I was born a slave”: Language, Sources, and Considering Descendant Communities.” Journal of the Early Republic 43, no. 1 (2023): 75-83; Harris, Leslie M. “Names, Terms, and Politics.” Journal of the Early Republic 43, no. 1 (2023): 149-154.
5) Jared Hardesty, Unfreedom: Slavery and Dependence in Eighteenth-Century Boston.
6) Catherine Adams and Elizabeth Pleck, Love of Freedom: Black Women in Colonial and Revolutionary New England (Oxford: Oxford University Press, 2010)
7) Wendy Warren, New England Bound: Slavery and Colonization in Early America.

