During my time as the 2019–2020 NULab Coordinator, I extended my previous research experience with the Women Writers Project to build an XSLT script for tokenizing element content for the Women Writers Vector Toolkit (WWVT). The WWVT is an online laboratory for learning about and experimenting with word embedding models and features over 20 models created using the Women Writers Online (WWO) corpus and parallel corpora created from the Text Creation Partnership collections. The WWVT models are created in R using the package “wordVectors” developed by Ben Schmidt and Jian Li and, using a spatial framework, can be used to study the relationships between words in a corpus of texts. That is, word embedding models calculate the spatial proximity and relationality of words across an entire corpus that can be explored through different access points and configurations like clusters and single word queries.
The research capabilities of word embedding models are rich, as Sarah Connell demonstrates in her exploration of seventeenth-century historiography. However, the previous models developed for the WWVT allow users only to interact with a corpora using single word queries. While useful, this approach does have its limitations. For example, if one is interested in geography in the WWO corpus, there are many different terms of interest: perhaps certain cities like London and Philadelphia or countries like Scotland or France. However, each of these examples is limited to a single word, and so querying multi-word locations like New York and Tower of London is less straightforward. When a word embedding model is made using the wordVectors package, a textual corpus is cleaned of certain punctuation marks like periods, asterisks, hyphens, and em dashes. After this process, the text is tokenized into individual units. Tokenization—a fundamental process for natural language processing—strips a string into individual units. Or, in this case, text into individual words. Therefore, when the word embedding model is created, it forms a relational model between the words of a corpus, not phrases or concepts.
After the first Word Vectors for the Thoughtful Humanist institute in 2019, the WWVT team sought to create expanded resources for scholars interested in word embedding models. One part of this project was to create a workflow that could provide opportunities to tokenize multiword strings in the word embedding models. In preparing participants’ corpora for the institute, I also developed a data preparation checklist with stages to identify “noise” that might disrupt the word embedding model, steps and tools for modifying and cleaning a corpus, and helpful resources for text regularization.
For XML corpora, an integral step in this workflow is to transform XML files to plaintext, a process in which we use the WWP Full Text XSLT on GitHub. In order to “tokenize” the content of specific XML elements, an additional step was needed before the documents became plaintext files. In principle, this process is rather straightforward: replace “noisy” characters in the element content that would be removed during the cleaning process and add underscores between words that should be treated as a single token. In application, however, this step became a bit challenging. When finding, modifying, or removing repetition in data, regular expressions are used to describe a sequence of characters that you wish to isolate. However, to figure out what you need to remove, you must first survey and identify the content that needs to be removed.
To tokenize the content of <persName> and <placeName> elements in the WWO Corpus, I—aided by the expertise of DSG XML Applications Programmer Ash Clark—surveyed the element contents for problematic punctuation, including hyphens, asterisks, en dashes, and spaces. After identifying the range of characters we needed to remove, we built an XSLT script to remove these characters and replace them with a single underscore. This XSLT script, the Element Tokenizer, is available with a detailed README tutorial on the WWP GitHub.
The tokenizer chains these transformations by declaring new variables for additional special characters in sequence. This means that the tokenizer processes all of the special characters before replacing them with underscores. These special characters were chosen specifically for the contents of the <persName> and <placeName> elements of the WWO corpus and do not include other punctuation because that either was not included or is cleaned in the model training process. To support work with other corpora, the Element Tokenizer has been annotated and directions for writing additional lines of code for different characters are included in comments.
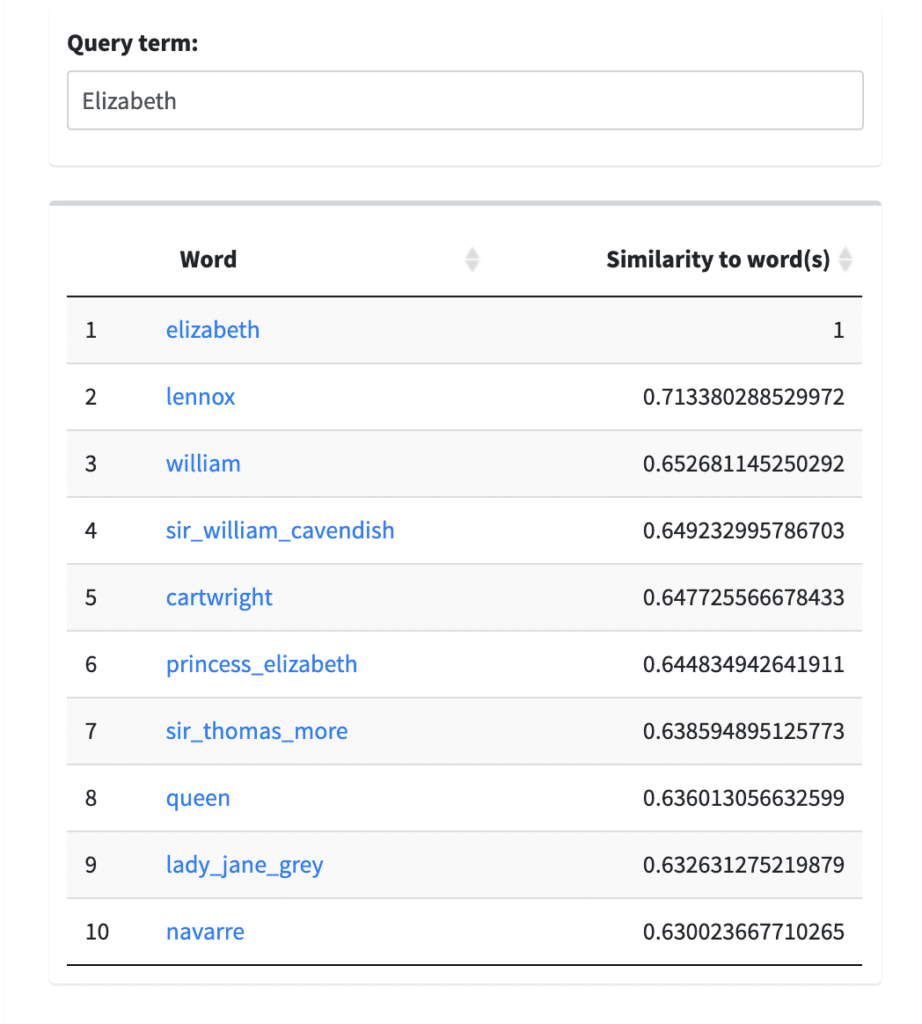
Using the Element Tokenizer, we created three distinct word embedding models: one with <persName> tokenized, another with <placeName> tokenized, and one with both <persName> and <placeName> tokenized. These models are available to explore now on the WWVT Lab. To demonstrate the effects of the tokenization process for words and concepts, the following examples compare two queries for “Elizabeth” and “London,” each a single word to represent names of people and places. I queried both of these terms in four different models to compare the results: the Full WWO Corpus (without any regularization or tokenization), WWO with Person Names Tokenized, WWO with Place Names Tokenized, and WWO with Place and Person Names Tokenized.
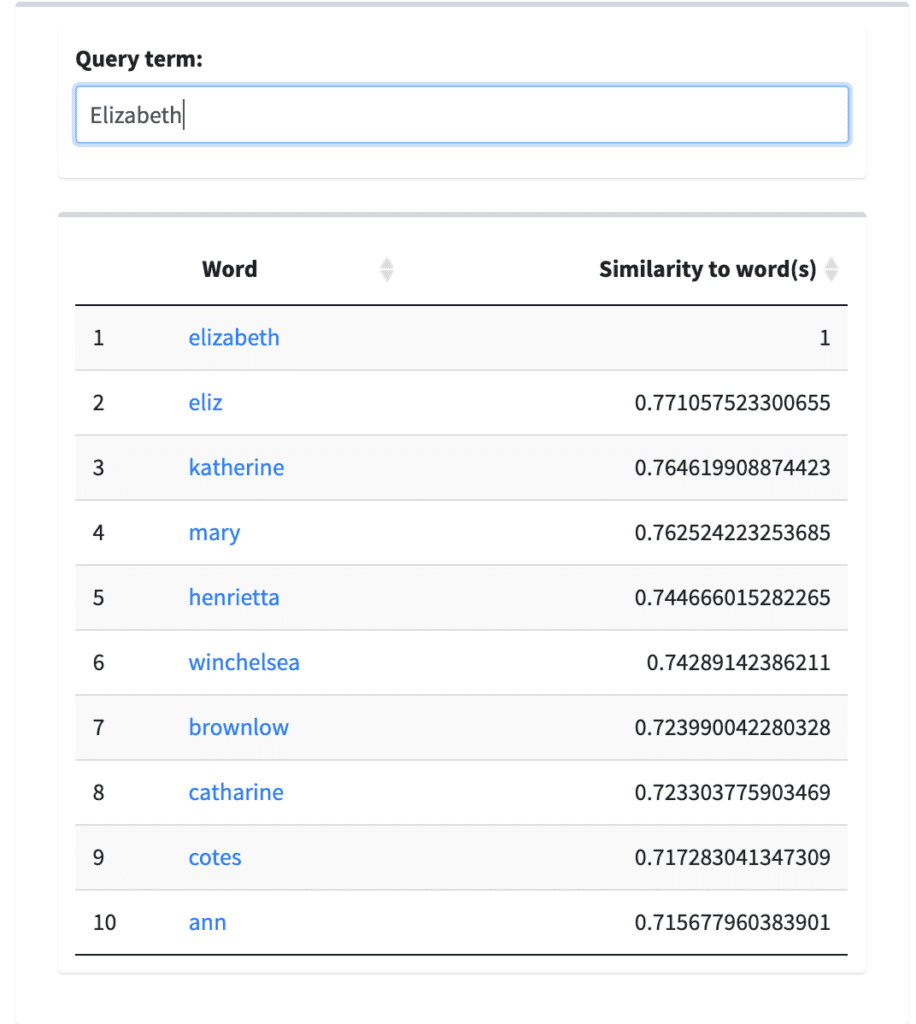

For the query term “Elizabeth” (Figure 1) the effects of tokenizing the <persName> element is striking; instead of generating a list of names that could be either first names or middle names with Elizabeth (i.e. Mary Elizabeth) or other possible women relations, the query for the tokenized model results in more proper, specific names: Sir William Cavendish, Princess Elizabeth, and Sir Thomas Moore. For a corpus like WWO—which includes many frequent, common names, like Elizabeth—tokenizing <persName> elements points to the possibility of more specificity to identify individuals in word embedding models, as demonstrated by the different vectors for “elizabeth” and “princess_elizabeth.”
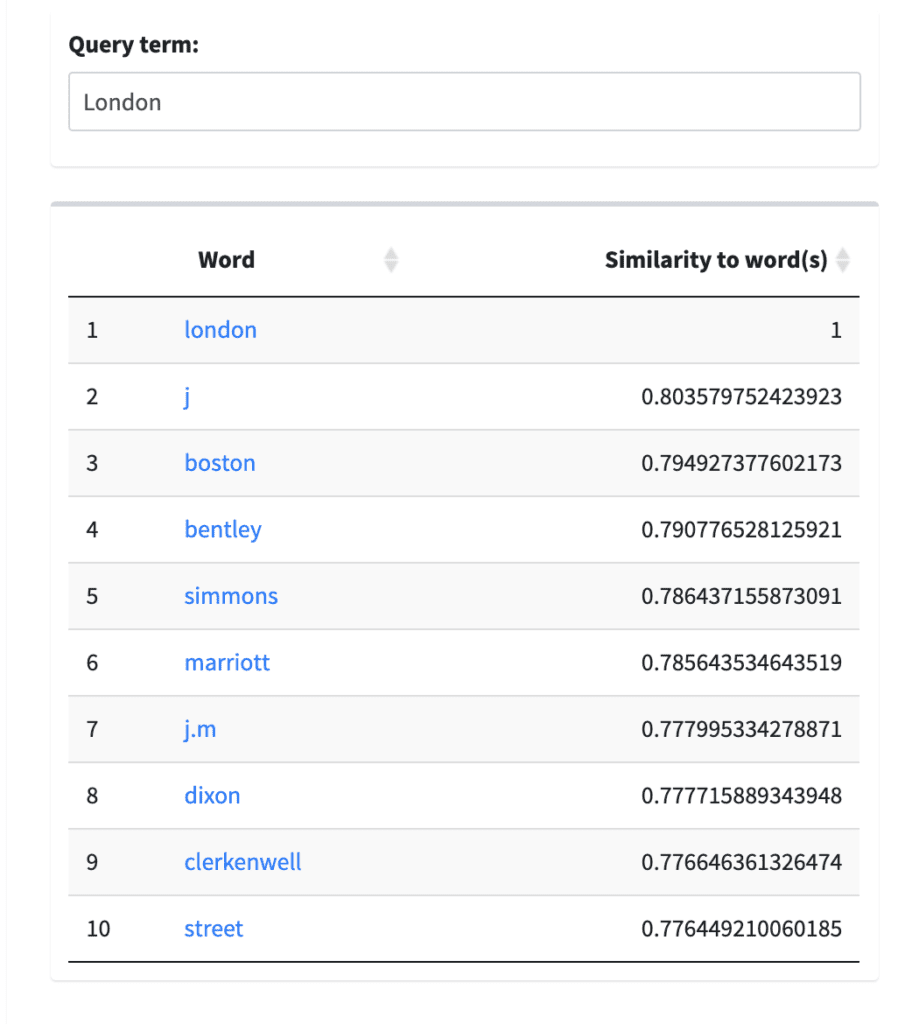
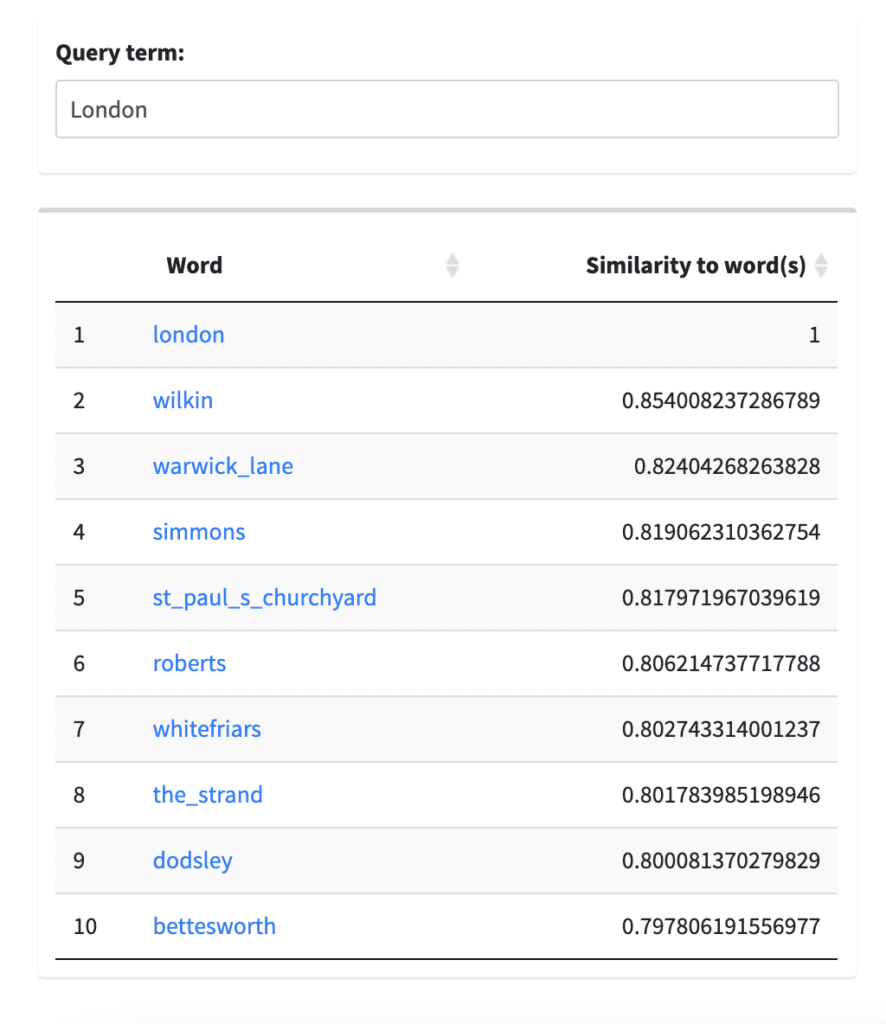
Similarly, for the query term “London” (Figure 2), there is a difference between the non-tokenized corpora results that points to specificity: in the WWO Full Corpus, the term London is connected to both possible place and person names, including “Bently” and “J.M.” However, the tokenized model results in specific locations and/or concepts including St. Paul’s Churchyard, the Strand, and Warwick Lane. For texts where proper names for people and places are instrumental to the concepts that researchers might be interested in using word embedding models for, tokenizing specific element contents is an exciting possibility to add another layer of analysis.
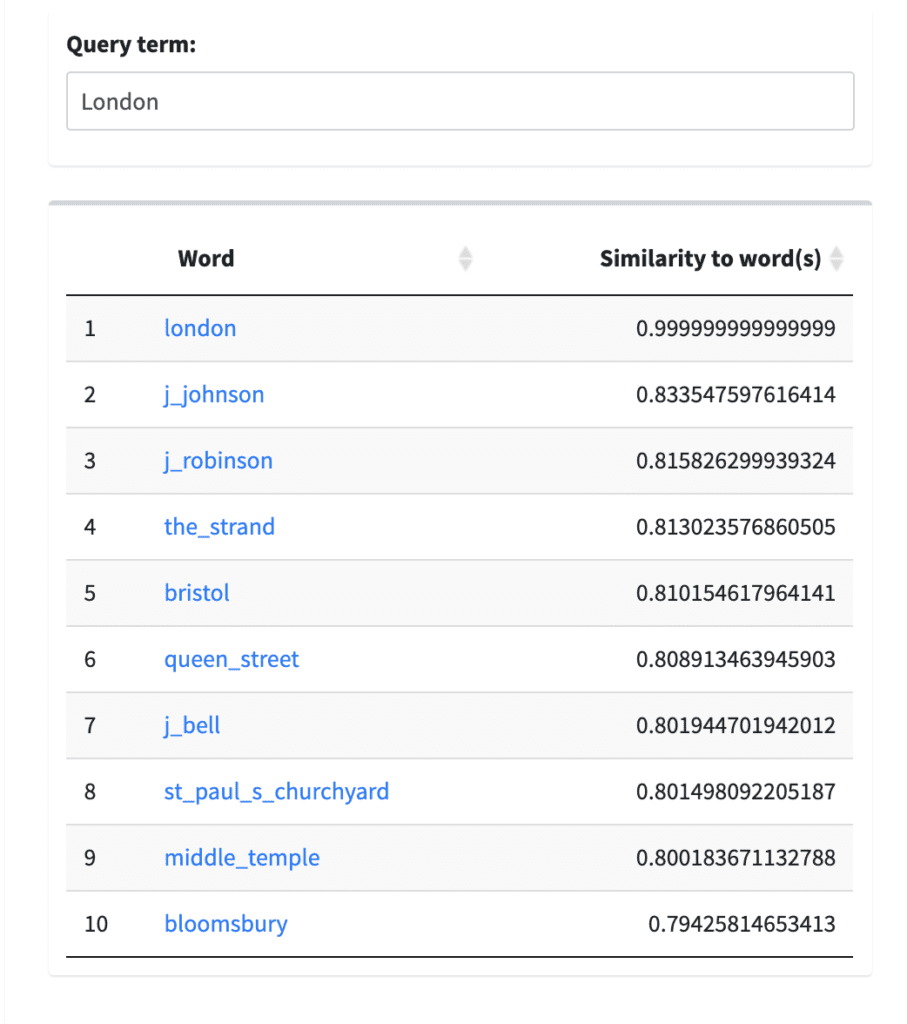
When you tokenize the contents of more than one element for a specific model (Figure 3), there is the possibility of overlap in concepts or topics like, in the above example, people and places. For example, the query term “London” in the Tokenized Person and Place Name model results in specific names and places like J.Johnson, and J. Robinson, The Strand, Middle Temple, and Queen Street. Without specific subject expertise or familiarity with the WWP corpora, an initial estimate could be a relationship between authors and locations of printers and print shops (as evidenced by the Strand). These types of names and places largely feature on title pages, so, to determine a more specific relationship, one could look at the location of these names within the original XML corpora for either a title page or other major structural elements. While this is only a speculation, this simple example with just two query terms demonstrates the possibility for specificity in results and spatial relationships when tokenizing element contents in XML corpora when using word embedding models.
While the Element Tokenizer XSLT script was developed for a very specific computational workflow for generating word embedding models from XML textual data, it demonstrates the possibility of altering existing workflows with simple tools for increased specificity, exploration, and access for subjects in computational textual analysis. For more reading about specific explorations of participant corpora from the WWP Word Vectors for the Thoughtful Humanist Institute Series, see the following blog post series:
Blog Posts from 2019 Institute Participants
Juniper Johnson: https://wwp.northeastern.edu/blog/archival-lgbt/
Sarah Connell: https://wwp.northeastern.edu/blog/credit-history/
James Clawson: https://jmclawson.net/blog/posts/updates-to-word-vector-utilities
https://wwp.northeastern.edu/blog/word-embedding-model-materialism-spiritualism/
Becky Standard: https://wwp.northeastern.edu/blog/a-most-illustrious-and-distinctive-career/
Juniper Johnson is a third-year Ph.D. student in the English Department studying Literature at Northeastern University. They focus on archives, queer and feminist theory, digital humanities, and eighteenth- and nineteenth-century American literature. Their research interests include archives and finding aids as data, writing about the body and sexuality in science and medicine, the history of queer theory, and disability studies.