By Hanyu Chwe
Stories are a vital part of the human experience. Narratives and tales communicate comedy, mystery, and drama to inform and entertain readers, listeners, or viewers. In search of a final project for our natural language processing (NLP) class, my collaborator (and fellow Network Science PhD student) Jessica Davis and I wanted to use NLP techniques to examine storytelling. Earlier this semester, we stumbled upon a paper (Reagan, Mitchell, Kiley, Danforth & Dodds, 2016) that introduced the idea of “emotional arcs.”
To create emotional arcs, both Reagan et. al and Jockers (2014) divide books into thousands of different word chunks and then use sentiment analysis to give an emotional score to that particular chunk. The sentiment analysis tool they use quantifies the emotional content of a passage; words like “sunshine” and “delightful” contribute to a happier score, while words like “dreary” and “murder” make the score sadder. Both authors trace the emotional score throughout the course of the book, describing the emotional arc of the narrative.
Reagan et. al don’t claim that an emotional arc necessarily reflects the plot or narrative of the book. Rather, the emotional arc reflects the reader’s emotional experience while reading the book; it’s just one part of the entire structure.
Interestingly, after tracing 1,327 novels from the Project Gutenberg corpus, Reagan et al. find that six archetypal emotional arcs describe the vast majority of those novels. These core arcs offer some evidence for the existence of common narratives and plot threads across stories, such as the hero’s journey described by Joseph Campbell. In addition, Reagan et al. find that books with certain core arcs are downloaded more frequently. For example, when comparing across all core arcs, books with an emotional arc that falls, rises, falls, and then rises again have the most downloads. That is, the emotional structure of a novel seems to correlate with success.
Jessica and I decided to use the techniques described in Reagan et al. and turn them to television. Of course, television is primarily a visual medium, but we relied on subtitle data to examine television shows through dialogue.
The vast majority of television scenes involve characters talking, so we hope that dialogue can accurately represent the emotional ebb and flow of a television show. Also, there’s good reason to expect emotional arc similarity in television. Sitcoms, police dramas, and other serialized television shows are often formulaic; tension is introduced at the beginning, then resolved, and the episode ends exactly where it started. Since many television episodes have similar structures, it’s not unreasonable to expect that they would have similar emotional arcs.
We obtained subtitle data from opensubtitles.org, a fan-maintained website devoted to uploading and housing millions of subtitle files. We were able to obtain all English subtitles of all English-language television shows in their database. Although the opensubtitles.org dataset doesn’t represent the entirety of all English-language television, it’s still a hefty amount: it contains 46,040 unique episodes representing 1,800 unique seasons of television. Note that due to its origin, the dataset likely suffers from some selection bias. It’s possible that popular shows (or at least shows popular among the website’s users demographics) are more likely to be represented in our data.
To construct episode-level arcs, Jessica and I divided each episode into twelve equally-sized time chunks. We divided by time to best reflect the viewer experience; dialogue does not appear uniformly throughout an episode. As a consequence, the amount of words in each time chunk differs dramatically throughout an episode. Also, since some television shows are much longer than others, some shows (mostly comedies) will have chunks with much fewer words than longer shows (mostly dramas). It’s possible that different chunk sizes bias our sentiment analysis, but we needed to keep the number of chunks in an arc constant.
We also traced the emotional arcs of individual television seasons by aggregating all episodes into a season and treating the aggregate like one really long television show. We only used seasons that had at least four episodes and did not use seasons that were incomplete or missing episodes. Season-level arcs are thirty-six chunks long. As with episode-level arcs, chunk size does differ considerably between seasons.
To assign scores to our chunks, we used VADER, a dictionary/rule-based sentiment analysis tool designed for social media analysis. VADER worked well for us since individual chunks of episode arcs can be quite small, and purely dictionary-based methods don’t work well on small pieces of text. Also, since all of our subtitle text is dialogue, we thought a tool designed for social media conversation would be appropriate.
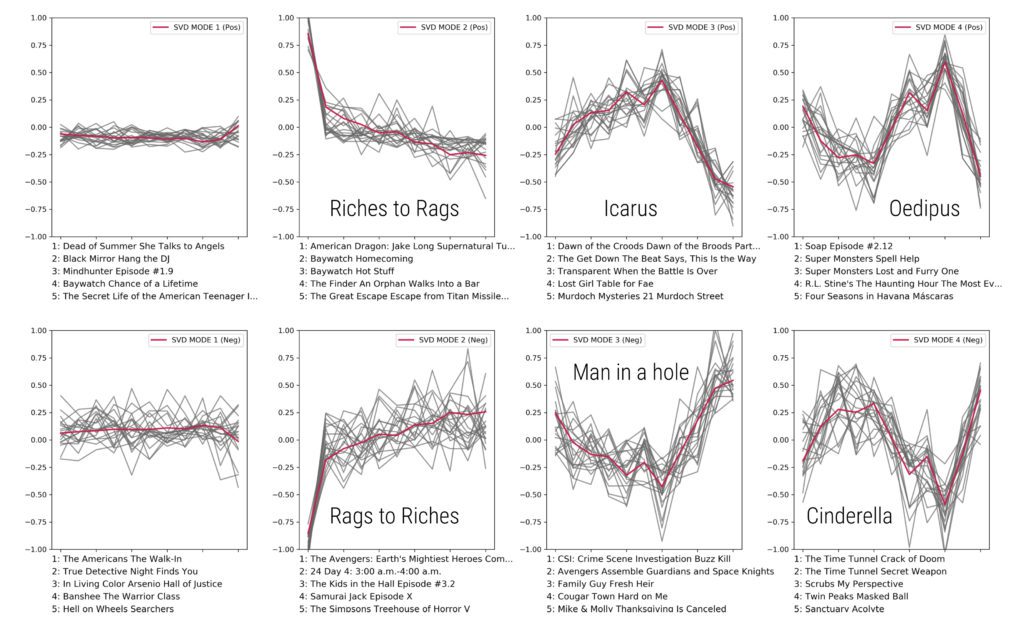
After creating arcs, we used singular value decomposition (SVD) and k-means clustering to generate core arcs and clusters in our subtitle data. Technically, SVD doesn’t cluster arcs, but it does give us “modal arcs” that best represent the overall data. The image above shows our SVD modes on individual episode data. Red lines represent the mode and gray lines represent the episodes that are best described by that mode. The top five best gray lines are listed below. Each episode arc is weighted by the inverse mode coefficient. We’ve added the names that Reagan et al. used to describe the six core emotional arcs they found. For example, an arc that starts sad but gets happier is a “rags to riches” arc.
In order to test whether or not our SVD modes actually reveal some emotional structure, we compared them to a “sentence salad model.” This means that, on both the episode and season levels, we shuffled sentences between the chunks so that we could keep the grammatical structure intact, but remove the larger story context. We expected our real SVD modes to differ dramatically from the “sentence salad” SVD modes. Finally, to test the success of emotional arcs, we gathered IMDB ratings for every episode. To get season-level ratings, we average all episode ratings together.
We don’t find the same resounding results that Reagan et. al did. Unfortunately, our k-means clustering approach found very little clustering behavior. However, our first four SVD arcs explain 48% of variance in the episode level data and 21% of the season level data. That is, our core arcs do an okay job of representing all of the thousands of emotional arcs we generated. This isn’t the same thing as clustering, but since our SVD arcs are very different from our ‘sentence salad’ arcs; we’re confident that our SVD arcs are meaningfully different. Finally, all of our SVD arcs had similar IMDB ratings; there is little correlation between arc and success.
Given the lack of clustering in our results, it’s possible that television shows aren’t as emotionally formulaic as they might appear. Alternatively, perhaps our results show that dialogue doesn’t accurately represent the narrative complexity of television.
Sources:
Reagan AJ, Mitchell L, Kiley D, Danforth CM, Dodds PS (2016) The emotional arcs of stories are dominated by six basic shapes. EPJ Data Science 5(31)
Hutto, C.J. & Gilbert, E.E. (2014). VADER: A Parsimonious Rule-based Model for Sentiment Analysis of Social Media Text. Eighth International Conference on Weblogs and Social Media (ICWSM-14). Ann Arbor, MI, June 2014.