Background Information
Since May of 2022 I have been working as a managing editor for the Digital Humanities Quarterly, an online, open-access, and peer-reviewed academic journal for digital humanities which has been in publication since 2007. As part of this work, I have been heavily involved in the maintenance and development of special projects for the journal. In early August, the editor-in-chief, Julia Flanders, asked if I would be willing to explore the feasibility of creating a topic model of the journal’s corpus of articles and I said yes. At the time I had very little familiarity with the idea behind, or methods for accomplishing this task. It was to be both an opportunity to work on a project which could be useful to the journal, and an opportunity to learn a new set of digital tools and skills as a Research Fellow for the NULab during the 2022-2023 academic year.
Topic modeling a corpus opens a number of analytical avenues for research, but at its core, the process is supposed to allow a researcher the ability to gain insights into a body of texts which would otherwise take an inordinate amount of time to read and understand without computational aid. The corpus of DHQ articles was approximately 640 texts at the beginning of the project, and so it was certainly a corpus which was large enough that the time required to read it all would be substantial. As I had worked earlier with a colleague on the editorial team, R.B. Faure, to develop a system of associated keywords for the journal, I found myself in the unique position of already being intimately familiar with the general themes and topics within the corpus. The experience of previously assigning keywords to each of the articles proved extremely valuable as I worked to assess each iteration of the topic model.
Learning MALLET
To start the project, my first step was to begin familiarizing myself with my chosen tool for the task, the MAchine Learning for LanguagE Toolkit (commonly called MALLET). MALLET is a particular method of topic modeling which uses Latent Dirichlet Allocation (LDA). As I am not a mathematician, nor an especially skilled programmer, I chose to take the advice of a tutorial for MALLET (found on programminghistorian.org), which recommends that when just beginning to learn topic modeling, it is both simpler and entirely reasonable to just trust that LDA works as intended. After following the instructions in the aforementioned tutorial by Shawn Graham, Scott Weingart, and Ian Milligan to install MALLET and run the program with its included test data, I was curious to see what would happen with “real world data.” I happened to have a CSV of approximately 500 article abstracts taken from different academic journals, and so I ran that corpus through MALLET a number of times to familiarize myself with how the program operates and what effect changing its various training parameters might have on the generation of each topic model. These initial tests showed very promising results, but also clearly reminded me that topic modeling with LDA results in an inference of presumed topical congruence, not a neutral description of topics in a corpus. In other words, setting training parameters for the model and reading the model’s results represents a two-fold assumption (Blei, 2012):
- There is a fixed number of discursive categories (topics) present in a given corpus.
- Each text within the corpus exhibits membership in these categories to some extent.
Preparing the Corpus
My earliest experiments with topic modeling did not yet use the DHQ article corpus. Each article is encoded according to a modified set of TEI standards in XML by the team of managing editors for “longevity and ease of management” (DHQ About page, 2023). This means that the publication of the journal’s articles is a unique academic project of its own. It also means that a rich set of implicit and explicit metadata is part of each article’s publication. Fortunately, I received help collating the article data and metadata from Ash Clark, who kindly created a number of TSV files for me using a script modified from work on the Women Writers Project. The most useful file contained the full text of each article, along with a number of metadata fields tracked for each article as well.
The next step was converting this TSV file into separate text files which could be introduced to MALLET as texts of a corpus. To do this, I wrote a short Python script which read the data in the TSV file and sorted it into an array. For each row in the array, the script then did the following:
- Read data in the column with the article’s full text and assigned it to a variable
- Simplify the text by converting it to ASCII characters (since MALLET cannot understand non-alphabetic characters nor ligatures) [Note 1]
- Read data in the column with the article’s DHQ ID number and assigned it to a variable
- Created a file with a unique name drawn from the ID number
- Wrote the full text of a single article to that file
- Repeated for each row of the array
Running this script now left me with a folder of approximately 640 text files ready to introduce to MALLET as a corpus for training.
Creating Stop Lists
When creating a topic model, there are a wide variety of parameters which influence the final outcome. Two extremely crucial ones are a researcher’s choice of stop words in the stop list, and how many topics the researcher specifies the corpus should be assigned. These two choices potentially have the largest impact on the construction and utility of the topic model as a method of analysis. The theory behind removing stop words from a corpus is that these small and arguably insignificant words only clutter the model with “topics” about nothing of substance. MALLET comes with a default stop list for English language corpora for this purpose, however, some scholars doubt the utility of comprehensive or highly customized stop lists (Schofield et al, 2017).
Intrigued by this article’s findings, I began to train iterations of a topic model without a stop list at all. This resulted in a number of topics which comprised top words like “a,” “the,” “that,” et cetera. Since these topics offered no insight other than the fact that DHQ authors used the necessarily common parts of speech, I began to draft a brief stop list which cut out only the words which appeared in these over-represented and non-specific topics. I iterated this list in collaboration with the managing editor team of DHQ, each of us looking over a current version of the list and questioning whether the words in it could have influential meaning in a text. After three versions of the list, I settled on a list which, in brief, excluded most prepositions, articles, pronouns, and forms of the verb “to be.” This current version of the stop list still allows for a number of traditionally excluded words, like “one” and “two” for example. The team of managing editors and I decided to leave these words in however, since human-based reading experience demonstrates that authors in DHQ frequently write about the novelty of their research (or lack thereof), and we anticipated this might be an interesting rhetorical topic to statistically analyze.
Determining the Number of Topics
MALLET has the capability to model any number of topics, so the next step after setting the stop list was to determine how many topics were appropriate for the DHQ article corpus. In practice, this step occurred somewhat simultaneously with the setting of the stop list, but it makes more sense to discuss each individually. Over the course of several months, I trained models with varying topic counts from ten to fifty. As I examined the results, I also learned that determining the “appropriate” number of topics to model a corpus is not at all an exact science. While there are a number of statistical data points generated with each training of a model, at a certain point this exercise in digital humanities also required a humanist analysis.
Choosing the appropriate number of topics took place in three phases. The first phase was to determine the lowest reasonable range for the number of topics. This was because it is generally considered desirable to model a corpus with as few topics as possible, since the main goal of the process is to make a large corpus legible and intelligible to a human reader. However, with smaller numbers of topics like ten, fifteen, and even twenty topics per model, each training result ended up largely incomparable to the previous attempt. In other words, the random element of MALLET’s training algorithm held far more sway than I wanted for the model, and it was up to chance what rhetorical or content-driven topics appeared in the model. This meant I thought the DHQ article corpus should have more than twenty topics prescribed for training a model, and so I then set about trying to determine how many more.
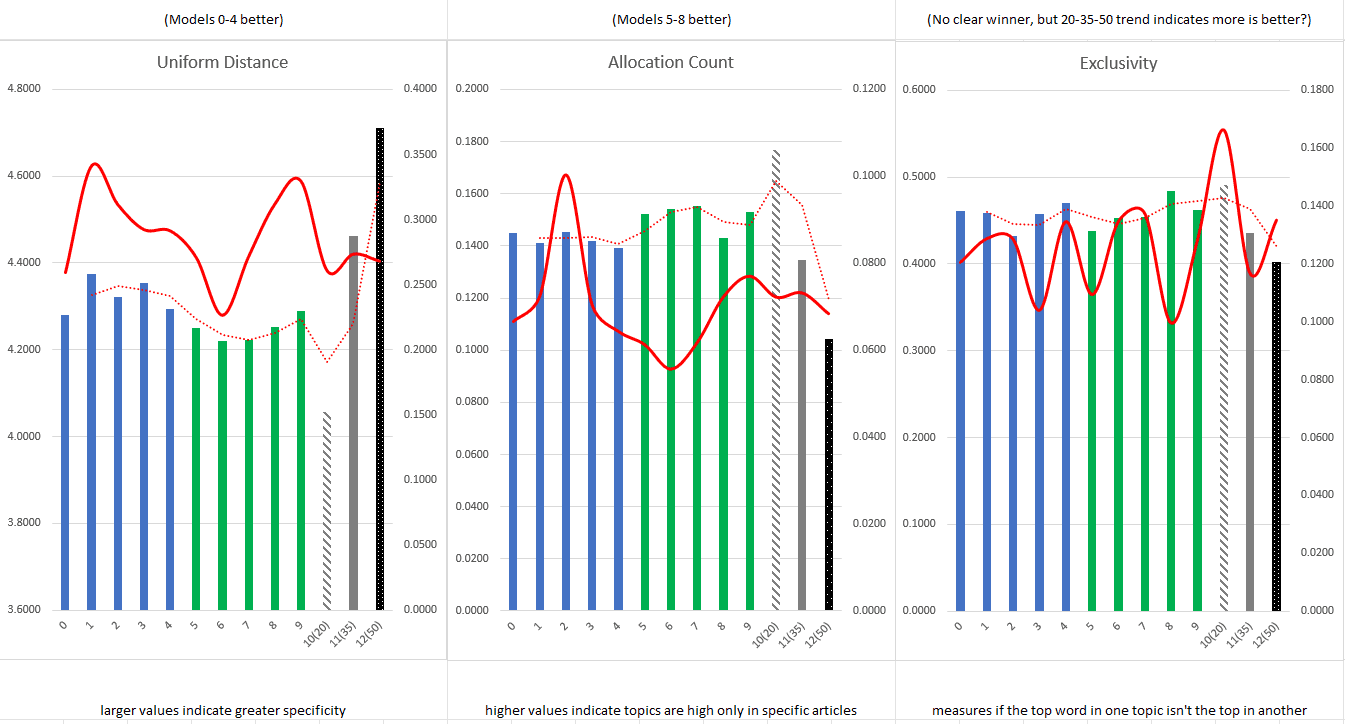
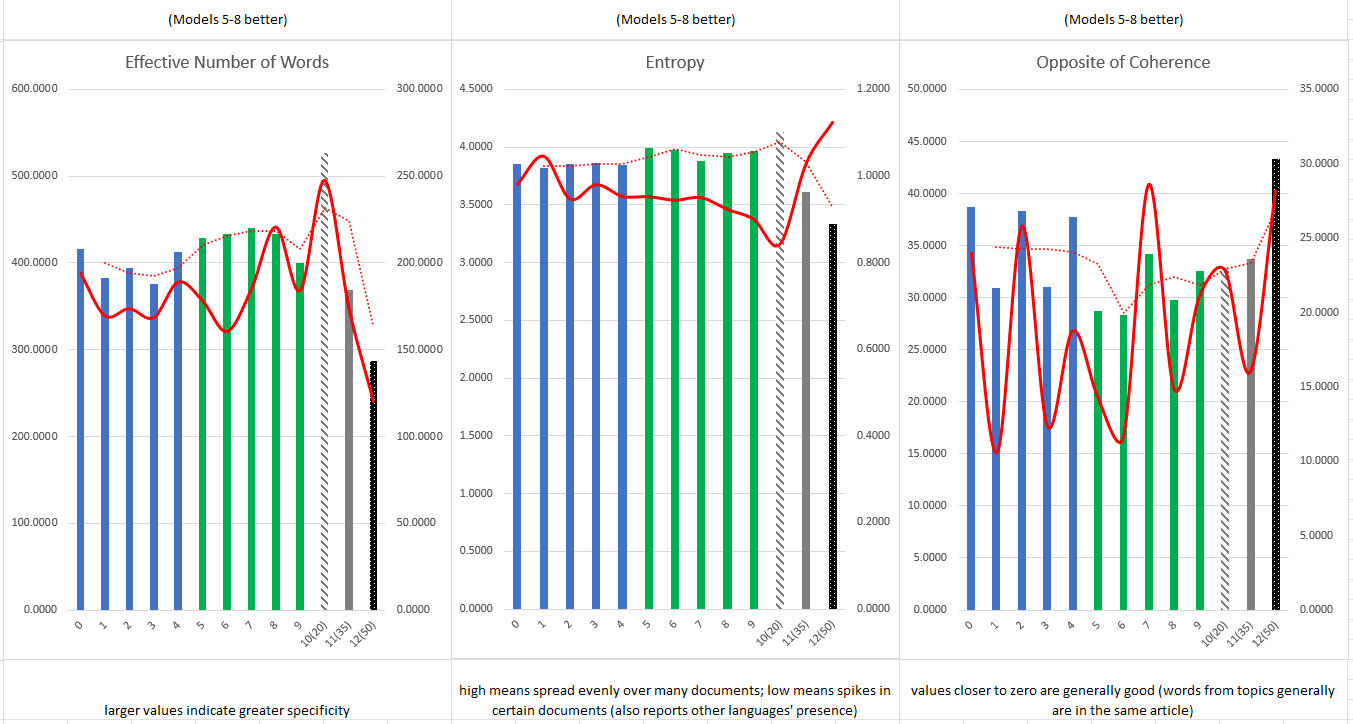
For this second phase, I trained models on twenty, thirty-five, and fifty topics. For each number of topics, I trained five models to help account for statistical anomalies and exported the diagnostic data from the training to an Excel spreadsheet. By graphing the metrics for coherence, exclusivity, uniform distance, and effective number of words (see Figure 1 below), I determined the most appropriate number of topics was likely somewhere between twenty and thirty-five. With this in mind, for the final phase, I compared twenty-five topics versus twenty-eight per model.

Using a similar procedure to the previous tests, I exported the diagnostic data of each trained model and created a series of graphs which tracked the average values and standard deviation of six different model metrics. These graphs included data from the most recent model training of twenty-five and twenty-eight topics, as well as one representative from each of the previous categories (twenty, thirty-five, and fifty). By including data from the previous iterations, I was able to see trends more easily in average values when the differences between twenty-five and twenty-eight topics were less clear. As shown in the graphs of Figures 2 and 3, the models trained to produce twenty-five topics performed better across all metrics (for my purposes) with the exception of uniform distance and a disappointingly unintelligible result for exclusivity [Note 2]. In general, twenty-five topic models displayed more consistent term allocation, had a higher effective number of words per topic, were more entropic across the corpus, and topic terms frequently cohered more often than in twenty-eight topic models [Note 3].
Choosing a Model
Topic modeling with MALLET does not generate the same results from the same parameters each time. This is because the training process utilizes a variable based on the system clock of the computer when MALLET is run to begin the process of associating tokens with a topic. So, to the digital humanist, some models trained with the same parameters may be “better” at representing the corpus of articles. Rather than picking one of the five models I had trained on the twenty-five topic parameter, I trained an entirely new set of twenty different complete models of the journal’s article corpus. Again, I exported the diagnostic data of each model, and calculated averages and standard deviations for a number of metrics using Excel. To help narrow down my choice in model, I devised a scoring system for each model’s average metrics and standard deviations. Each time a model was above or below the average (depending on which was desirable), I awarded it one point [Note 4]. Models 007, 008, and 015 scored highest according to this metric. Models 007 and 008 slightly edged out 015, so I set about qualitatively comparing those two options.
I began by attempting to cross reference the two models’ topics. Because topics are numerically disambiguated randomly, there is no reason that Topic 05 of Model 007 should match with Topic 05 of Model 008. So, I gave each of the twenty-five topics of Model 007 an alphabetic label as well and began trying to see if topics in Model 008 had roughly equivalent top terms. For topics which were highly weighted in the models, there appeared to be many similar topics across the models. As topics became less heavily weighted (and less coherent) however, it became very difficult to draw parallels between the models. Attempting to cross reference the models helped determine that some topics across models were similar, but ultimately choosing a single model would be a choice which ruled out some potentially interesting topics no matter what.
In the end, I selected Model 008 as my preferred model (see the top terms in Model 008 of Figure 4 below). This particular model has a large majority of top terms and top bigrams which appear to intuitively match well with the keyword system developed for DHQ over the past few years. As I began the process of drafting descriptive titles for each topic of Model 008, I was also pleased to realize this model’s top terms and bigrams seemed to frequently be related to a single, humanly intelligible discursive category. This is, if you remember, the ideal result of training a topic model. The heaviest and lightest weighted topics do have some indications of smaller sub-categories within them, but by and large the middling topics are coherent to my eyes.

Next Steps
The next major steps in this project have already begun, but are largely outside the scope of this year’s research and this (not so brief) blog post. In the coming weeks, the editorial team and I will meet to discuss the drafted titles of topics in Model 008. The per article data on topic membership has already been correlated with article-level metadata from the journal. Correlating these data sets allows the process of analyzing the topic model to begin. With information on authorship, cited reference counts, article lengths, publication dates, and more, there are a host of questions about which we may be able to infer the answers. For example, do authors writing about the topic tentatively termed “Teaching and Learning in Digital Humanities” tend to cite more references in their articles than those writing about “Art in Digital Humanities”? Do articles which appear to largely include conversations about institutional collaboration actually demonstrate collaboration through multi-authored articles? Or very simply, how have the topics varied in frequency over time?
Later this summer, work with the model will continue. In addition to the questions listed above, I plan to correlate it with the keyword system developed for DHQ in an attempt to gauge the comprehensiveness of the keywords, and ideally highlight any gaps in its coverage. Each model was also trained to produce an “inferencer” from the corpus, so it may be possible to satisfyingly model the corpus of DHQ abstracts using the same topics. Finally (with thanks to Alyssa Smith for the initial suggestion), the model may also be incorporated into a “what to read next” recommender system for the journal.
Resources Consulted and Recommended Reading
- Graham, Shawn, Scott Weingart, and Ian Milligan. “Getting Started with Topic Modeling and MALLET.” Programming Historian 1, 2012. https://doi.org/10.46430/phen0017.
- Kapadia, Shashank. “Evaluate Topic Models: Latent Dirichlet Allocation (LDA).” Medium, December 24, 2022. https://towardsdatascience.com/evaluate-topic-model-in-python-latent-dirichlet-allocation-lda-7d57484bb5d0.
- Kleymann, Rabea, Andreas Niekler, and Manuel Burghardt. “Conceptual Forays: A Corpus-Based Study of ‘Theory’ in Digital Humanities Journals.” Journal of Cultural Analytics 7, no. 4 (December 19, 2022). https://doi.org/10.22148/001c.55507.
- Mimmo, David. “Topic Model Diagnostics.” Accessed April 18, 2023. https://mallet.cs.umass.edu/diagnostics.php.
- Pedro, João. “Understanding Topic Coherence Measures.” Medium, January 10, 2022. https://towardsdatascience.com/understanding-topic-coherence-measures-4aa41339634c.
- Schofield, Alexandra, Måns Magnusson, and David Mimno. “Pulling out the stops: Rethinking stopword removal for topic models.” In Proceedings of the 15th Conference of the European Chapter of the Association for Computational Linguistics: Volume 2, short papers, pp. 432-436. 2017. https://aclanthology.org/E17-2069
- Underwood, Ted. “Topic Modeling Made Just Simple Enough.” The Stone and the Shell (blog), April 7, 2012. https://tedunderwood.com/2012/04/07/topic-modeling-made-just-simple-enough/.
- Wallach, Hanna M., Iain Murray, Ruslan Salakhutdinov, and David Mimno. “Evaluation Methods for Topic Models.” In Proceedings of the 26th Annual International Conference on Machine Learning, 1105–12. Montreal Quebec Canada: ACM, 2009. https://doi.org/10.1145/1553374.1553515.
- Weingart, Scott. “Topic Modeling for Humanists: A Guided Tour.” the scottbot irregular, July 25, 2012. http://www.scottbot.net/HIAL/?p=19113.
Notes
- By creating a python script which accomplished this task, the text simplification process removed characters which had diacritic marks and any characters beyond the standard English alphabet or numbers. [continue reading]
- As explained by David Mimmo on the official MALLET website, uniform distance is a measure of topic specificity where larger values indicate higher specificity. Exclusivity tracks when the top terms of a topic are not also the top terms in another topic. You can find Mimmo’s explanations at: https://mallet.cs.umass.edu/diagnostics.php [continue reading]
- Again from Mimmo, allocation count indicates when a topic is highly present, but only in certain articles. The effective number of words indicates greater specificity when its value is high (similar to uniform distance, but performed with a different calculation). Entropy reports the probability of finding a topic in any given document. This metric is difficult to assign a clear preference of high or low values since both extremes indicate potential issues with a trained model. Since I was more interested in the corpus as a whole, I chose to prefer higher entropy. Models score closer to zero in coherence when their top terms tend to appear together in the same document. [continue reading]
- This scoring system is (admittedly) the least quantitatively satisfying part of my methodology in this project. While some values displayed much clearer trends across models, I opted to score success in each metric with the same weight (1 point) because at this point I was still choosing a trained model. The insights which may in the future tell me that coherence, for example, might actually be one of the most important metrics for my purposes were impossible to have at this point. Later work on this project may require a return to these competing 28-topic models to select one more appropriately suited to the questions asked of it. [continue reading]