On October 6th, 2021, the NULab for Digital Humanities and Computational Social Science hosted the sixth annual “Speed Data-ing” event, a research showcase that brought together potential collaborators to discuss a range of digital humanities and computational social science research questions, methodologies, and data sets. This year, Speed Data-ing was held in collaboration with the Digital Scholarship Group as part of the Digital Humanities Open Office Hour series.
Matthew Gin, an Assistant Teaching Professor in Architecture, began the event by discussing his recent work studying temporal structures built for festivals in eighteenth-century France. Due to the ephemeral nature of these structures, Gin finds himself in the position of an architectural historian without any actual physical architecture to study. The data that he works with are the materials generated in the process of creating and building these structures, i.e. workers contracts, descriptions given for government records, and so on. Gin is currently researching the temporary buildings built on the frontiers of France, specifically on an island. These structures were built as part of a ceremony of handing over foreign royal wives to their French husbands. He aims to try and reconstruct these ‘nowhere spaces’ that had a large social impact in their times but left no long-term physical traces. He is interested in the structures themselves, but also importantly their urban context. To learn more about Gin’s research, see his Northeastern profile.
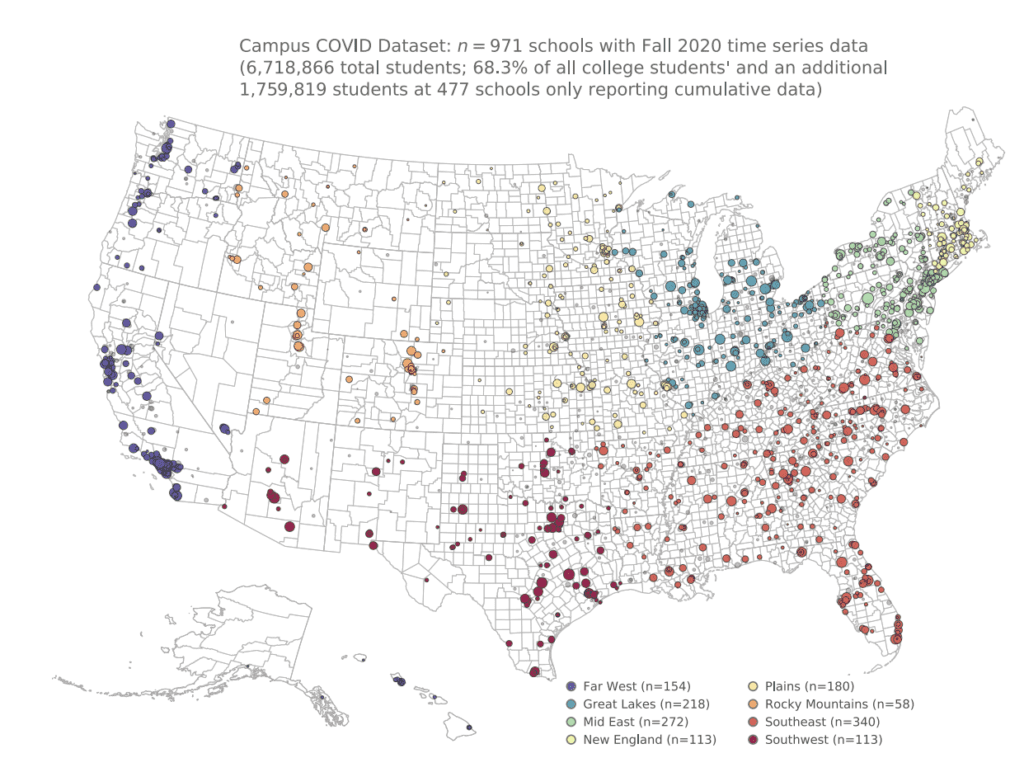
Next, Brennan Klein, a postdoctoral researcher for the Network Science Institute, discussed a series of datasets related to the COVID-19 pandemic. He shared three distinct datasets: university teaching and case counts from fall 2020, the impact of the pandemic in K-12 schools in Massachusetts in terms of test scores, and the bias in decarceration during the pandemic. Klein notes that he has not used the dataset on K-12 test scores for research, but believes it could be a great source. In terms of the data involving university testing, Klein found, perhaps unsurprisingly, that universities that do not test are missing many low-symptom cases that result in more community spread. Klein critically evaluated the decarceration rates during the pandemic, with a focus on racial disparities. He argued that decarceration during COVID-19 is not an objective public health plan because it disproportionately resulted in the result of white inmates. To learn more about Klein’s research, see his Northeastern profile.
Amy Ruskin, a Data Engineer from the Digital Scholarship Group, shared her ongoing work focused on public art in Boston, especially areas like Roxbury and Chinatown. Ruskin highlighted the process of getting her data on public art into Wikidata. Wikidata is a free collaborative knowledge space under the umbrella of Wikimedia. Ruskin demonstrated what items look like in Wikidata, and made an argument for why it is a good resource for the public art project. Wikidata can handle a lot of information in a structural way and can capture movement of public art by including location data with start and end times. Ruskin notes that Wikidata is a multilingual site, and allows for multilingual labels on datasets where only the labels are transformed. To put it another way, the content of the data remains consistent even as you can change language options. This public art project has its own Wiki project page, where all of its relevant datasets can be centrally located. To learn more about Ruskin’s research, see her Northeastern profile.
Silvio Amir, an Assistant Professor in Khoury College of Computer Sciences, discussed his process for making analysis of social media data more representative of overall populations. His research involves using social media analysis to determine the prevalence of mental illness, in an effort to better deliver treatment to the right populations at the right time. Amir explained how he adapted methodologies commonly used in health studies for social media analysis. His work asks: how can we leverage user-level models to obtain valid population-level estimates? He illuminates the need for more critical thinking around social media analysis for it to be useful and representative of the population at large. To learn more about Amir’s research, see his personal website.
The session concluded with a productive question and answer portion, where the speakers and audience shared resources with each other. A notable resource from this exchange is the Python package Tabula, which automatically reads PDF tables and turns it into data. This package gets rid of the laborious process of manually copying information from a table into a dataset for manipulation, interpretation, and visualization.
If you have any leads for these coming projects or are interested in becoming involved with collaborative research at the NULab, please reach out to us at [email protected].