This post was authored as part of a Northeastern TIER 1 project, led by NULab faculty.
By Jonathan Fitzgerald, Ph.D. Candidate in English, Northeastern University
I remember the first time I trained a topic model. It was in a course called Humanities Data Analysis, taught by Ben Schmidt. He provided us a corpus of the Federalist Papers and some code that he adapted from David Mimno, contributor to the original MALLET package and author of the R implementation of MALLET. After the initial confusion–“topics” aren’t topics in the traditional sense, after all–it felt like magic. The computer read the corpus and derived some topics!
Enthusiasm for topic modeling remains strong in DH in part because it is a useful way to reduce a corpus down to manageable chunks and to get a sense as to what individual documents are “about.” That said, in the years since my first experiments with the Federalist Papers, I’ve come to believe that topic modeling is perhaps most useful as part of a workflow aimed at some goal beyond identifying topics in a corpus. To that end, I’ve been using topics to seed a genre classifier in my work with the Viral Texts Project.
While I’ve been working with topic models these past few years, a new modeling craze has taken DH by storm…relatively speaking. That is, thanks in large part to this post by Ben Schmidt, DH’ers have enthusiastically adopted word embedding models (WEMs), particularly the most popular manifestation, word2vec, created by Tomas Mikolov and his colleagues at Google.
In a post in which we announced our current project “Word Vector Analysis for TEI/XML: A user-Friendly Toolkit,” my colleague Liz Polcha offers a helpful introduction to word embedding models and the way we plan to use them with data from Women Writers Online. As part of that effort, I’ve been tasked with experimenting with word2vec and our corpus, as well as with imagining a way to provide an interactive online user interface. All this work is in progress, but as a part of those efforts, I’ve been thinking about what we can actually do with word embedding models. Just as my experience with topic models led me to the conclusion that they are most helpful on the way to some other interpretive exercise, my sense is that the same may be true for word embedding models.
This sense is born out of my own experiments with word2vec, but also from the existing literature on word embedding models. That is, you probably won’t read a write-up on word2vec that doesn’t provide the classic analogy example about kings and queens. And, to be sure, it’s cool. That word vectors seem to reflect expected relationships between words is solid evidence for their potential usefulness. But beyond seeing words related to other words and parsing out analogous relationships between terms, what can we do with word embedding models?
I have a few ideas. For one, to stay on the topic of this post (pun!), though word embedding models are unsupervised algorithms, we can work with the models in a way that is akin to a kind of supervised topic modeling. Topic modeling derives “topics” from a corpus starting with a random seed word and grouping words that frequently co-occur within a document; working with the output of a word embedding model, on the other hand, lets us set that seed, so to speak. As Ben Schmidt writes, “You could think of this as a supervised form of topic modeling: it lets you assemble a list of words that typically appear in similar contexts.” A significant difference between topic models and word embedding models is that topics are generated with an awareness of the documents in a corpus. Word embedding models, on the other hand, look across an entire corpus for word collocations within a narrowly defined context, sometimes referred to as a “window.” Or, as Schmidt defines the difference, “A topic model aims to reduce words down [to] some core meaning so you can see what each individual document in a library is really about. Effectively, this is about getting rid of words so we can understand documents more clearly. WEMs do nearly the opposite: they try to ignore information about individual documents so that you can better understand the relationships between words.”
Schmidt’s food example from the Chronicling America corpus illustrates the way we can use the relationship between words to build a kind of supervised topic. He starts with one food word, “oysters,” and finds other food words that appear in similar semantic contexts: “ham,” “bread,” “chicken.” Then, he adds these terms to the original vector and runs the search again, adding even more food words. In a way, he is building a “food” topic. The process is, of course, different from what topic modeling does, but the end result is a list of words that have a meaningful relationship within a corpus of texts—except the topics are created rather than derived.
In unsupervised machine learning, the algorithm does not explicitly “know” what we are searching for; in the above example, it does not know that “oysters”, “ham”, and “bread” are foods. It just knows they cooccur. But when a human researcher intentionally selects and combines these words into a vector that she describes as food words, the unsupervised algorithm is being used in a supervised way.
This notion of creating topics through a supervised process of selecting and combining also works to allay an anxiety I have about the opaqueness of unsupervised modeling (particularly for a humanist who is new to computational modeling!). Ted Underwood frames the issue in a recent blog post in which he argues, among other things, that we should “make quantitative methods more explicit about their grounding in interpretive communities.” That is, we shouldn’t let computational models stand in for humanistic interpretation. Underwood writes: “Researchers are attracted to unsupervised methods like topic modeling in part because those methods seem to generate analytic categories that are entirely untainted by arbitrary human choices. But as [Stanley] Fish explained, you can’t escape making choices.”
Underwood emphasizes the importance of grounding these choices (or, interpretations) in “interpretive communities.” And, for his part, Underwood notes that one way to do this is to favor supervised modelling methods; he writes:
I have been leaning on supervised algorithms a lot lately—not because they’re easier to test or more reliable than unsupervised ones—but because they explicitly acknowledge that interpretation has to be anchored in human history.
I like this notion of relying on human judgment and generating interpretations “anchored in human history.” That is, after all, what makes us humanists, right? To that end—and again acknowledging that word2vec is an unsupervised algorithm—I’ve been thinking about the ways we can ground our work with unsupervised models in human interpretation.
Particularly, I’m interested in the potential for examining if and how word usage might reflect broad cultural trends over time. In the WWO corpus, which covers the 16th through 19th centuries, it might be interesting to consider how the use of the word “freedom” reflects the culture of the authors who use the word. I approached this question by dividing our corpus up by century and creating “supervised topics” based on the word “freedom.”1Following Schmidt’s example, I searched first for the word “freedom,” and then iteratively selected additional words that made contextual sense—so, in the 17th-century corpus, “liberty” is in, “disdain” is out.
In the 16th and 17th centuries,2Women Writers Online contains texts with publication dates from 1525 to 1850; there are 30 texts from the 16th century and 170 from the 17th, so for the purposes of this analysis, I combined these texts. freedom seems to be a more personal affair; words that show up in the same vector space as “freedom” include “happiness,” “friendship,” and “wedlock.”
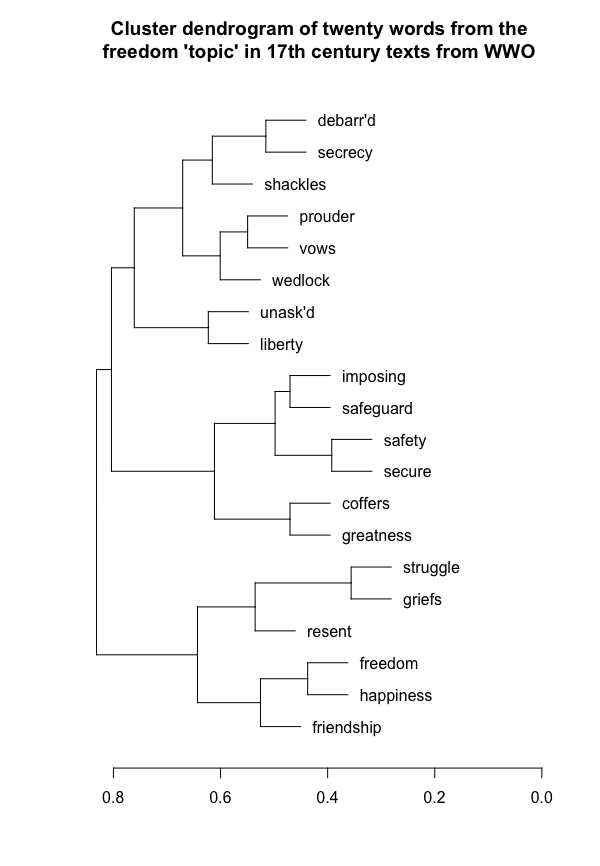
In the eighteenth century, freedom takes on a particularly revolutionary bent: “patriots,” “rights,” “triumph,” “country’s,” and “tyrants,” for example.

Finally, in the nineteenth century, the revolutionary language remains (“rights,” “tyranny”)—though diminishes some—and a new kind of freedom (or lack thereof) appears in the form of words like “slave,” “slaves,” “enslave,” “degrading,” “minority.”

I considered that these shifts might be geographically-contingent; after all, only one work in our corpus from the 17th century was published in the colonies. However, in the 18th century, when we see a lot of what I’ve described as “revolutionary” language, Europe still dominates as place of publication. It’s not until the 19th century that the number of works published in the United States even begins to come close to those published in Europe (34 in the U.S. and 54 in Europe). So it seems that geography does not have a significant impact on the way the word “freedom” is used in our corpus across three centuries, if only because of the collection’s own unevenness in its inclusion of works published outside of the United Kingdom.
Treating these vectors like supervised topics allows us to consider interesting cultural questions through the lens of the WWO corpus. But, typically word embedding models are deployed to tell us something about the words themselves. In this sense we can use a similar process to consider the way a word’s usage shifted over time. My colleague Sarah Connell suggested that “grace” might make for an interesting test case. And indeed, when compared across centuries, “grace” moves from a word typically used in religious contexts in relation to God’s grace (e.g., “mercie,” “wisdome,” “fatherlie,” “redeemer,” “almightie”; note the archaic spellings) to secular contexts in relation to women’s beauty (e.g., “beauty,” “charms,” “fair,” “virtue,” “sweetness,” “smile,” “lovely”). Of course, the meaning of the word hasn’t changed, but its application has. And, as with “freedom,” this can tell us something about shifting cultural contexts—in this case secularization.
In fact, this shift toward secularization is confirmed in our corpus using another method. The WWP’s previous experimentation with markup-based exploration has already shown how growing literary secularization manifests in the collection after the seventeenth century. For one example, of the 3,228 bibliographic citations in the WWP’s sixteenth- and seventeenth-century materials, 3,689 (86%) contain biblical references; by contrast, 256 (15%) of the 1,742 eighteenth-century bibliographic citations are biblical references.3Taking genre into account by restricting the search to texts marked in the WWP’s metadata as containing verse still reveals considerable differences between periods; 778 (92%) out of 873 pre-eighteenth-century citations are biblical references while 240 (34%) out of 705 eighteenth-century citations are biblical.
In both examples, word2vec gives us words that appear in similar contexts to our seed words, but it is up to us to recognize these similarities as significant, intentionally group them into ever more expansive topics, and then to theorize what (if anything) these collocation patterns might mean. Thus, we can work with an unsupervised model in a way that acknowledges, to quote Underwood once more, “we’re no longer just modeling language; we can model interpretive communities at the same time.”
We’re still early on in our explorations of word embedding models and literary corpora, both at the WWP and in DH in general. But that, in part, is what makes this project so interesting to us: it’s an opportunity to explore word embedding models on a corpus that is focused on gender, relatively free of digitization errors, and easily transformed into markup-based subcorpora using XSLT and XQuery.
As we continue to work with this corpus, it’d be helpful to know what potential users might be interested in. If you have any suggestions for possible use-cases, please let us know in the comments.